Warum überparametrisierte neuronale Netzwerke nicht Overfitten: Ein mathematisches Paradox


GPT-4 hat mehr Parameter als die Menschheit Bücher geschrieben hat. Laut klassischer Statistik müsste ein solches Modell bei neuen Daten katastrophal versagen. Stattdessen funktioniert es außergewöhnlich gut. Dieser Artikel erklärt, warum.
Stell dir vor, du baust ein Haus mit hundertmal mehr Säulen, als das Dach physikalisch benötigt. Jedes Ingenieurshandbuch würde sagen: Das ist instabil, ineffizient und bricht unter dem eigenen Gewicht zusammen. In der Welt moderner KI-Modelle ist genau das das Erfolgsrezept.
Traditionell gilt in der Statistik Occams Rasiermesser: Wähle das einfachste Modell, das die Daten erklärt. Zu viele Parameter führen zu Overfitting, das Modell lernt die Trainingsdaten auswendig und versagt bei neuen Eingaben. Es ist, als würde ein Student die Aufgaben der Übungsblätter auswendig lernen, statt das zugrundeliegende Prinzip zu verstehen. In der Prüfung, mit neuen Aufgaben, scheitert er.
Moderne Deep-Learning-Modelle haben oft mehr Parameter als Trainingsdatenpunkte sie befinden sich im sogenannten Interpolations-Regime. Laut Lehrbuch müssten sie katastrophal scheitern. Tun sie aber nicht. Die Frage, warum, ist eine der interessantesten offenen Fragen der mathematischen Lerntheorie.
Um das Paradox zu verstehen, lohnt sich zunächst ein Blick auf das, was wir zu wissen glaubten.
Jedes statistische Modell bewegt sich in einem Spannungsfeld zwischen zwei Fehlerquellen. Ein zu einfaches Modellhat hohen Bias: Es unterschätzt die Komplexität der Daten, eine gerade Linie für eine wellige Datenkurve. Es underfittet. Ein zu komplexes Modell hat hohe Varianz: Es überfittet, passt sich jedem Messrauschen an, verliert den globalen Trend aus dem Blick. Die Linie geht perfekt durch jeden verrauschten Punkt, trifft aber keine einzige neue Vorhersage.
Das Resultat ist eine U-Kurve: Der Testfehler sinkt zunächst mit zunehmender Modellkomplexität, das Modell lernt echte Muster, und steigt dann wieder an, sobald das Modell beginnt, Rauschen als Signal zu interpretieren. Die Lehrbuchlösung war klar: Kalibriere die Komplexität so, dass du im Minimum der U-Kurve landest. Nicht zu einfach, nicht zu komplex.
Jahrzehntelang war das die Grundlage für Modellauswahl, Regularisierung und Kreuzvalidierung. Es funktionierte. Bis die Modelle groß genug wurden, um die Grenze der perfekten Datenanpassung zu überschreiten.
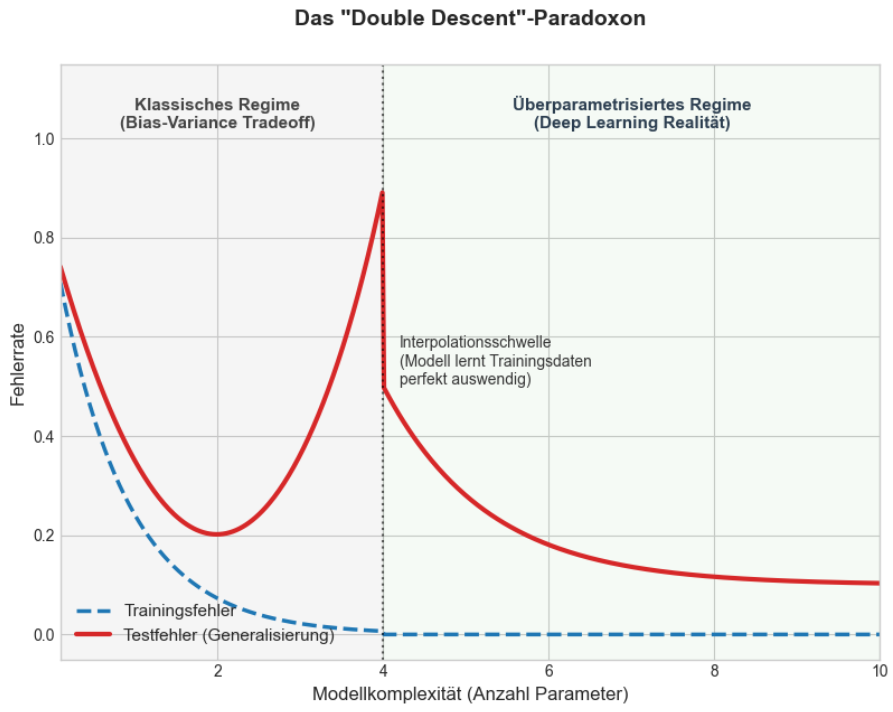
2019 publizierten Belkin, Hsu, Ma und Mandal eine Arbeit, die die Lerntheorie in Erklärungsnot brachte. Sie zeigten systematisch, was Praktiker bei der Arbeit mit tiefen Netzen schon beobachtet hatten, ohne es benennen zu können: Wenn man die Modellkomplexität über die Interpolationsschwelle hinaus erhöht, über den Punkt, an dem das Modell die Trainingsdaten perfekt anpassen kann, passiert etwas Unerwartetes. Der Testfehler sinkt erneut.
Die Fehlerkurve hat damit nicht eine, sondern zwei Täler. Zwischen beiden liegt ein Peak, genau an der Interpolationsschwelle, wo das Modell gerade groß genug ist, die Daten perfekt zu fitten, aber noch nicht groß genug, um flexibel zu sein. Nakkiran et al. (2021) bestätigten dieses Phänomen empirisch in modernen Architekturen wie ResNets und Transformern, also genau den Modellen, die in der Praxis eingesetzt werden.
Ein Modell interpoliert, wenn es jeden Trainingsdatenpunkt exakt trifft, der Trainingsfehler ist null. Unterhalb dieser Schwelle kann das Modell die Daten nicht vollständig anpassen. Oberhalb existieren unendlich viele mathematische Funktionen, die alle Trainingsdaten perfekt beschreiben. Das Modell hat Freiheit in der Auswahl, und genau diese Freiheit ist entscheidend.
Die entscheidende Intuition: Wenn ein Netz riesig ist, gibt es nicht eine perfekte Lösung, sondern einen ganzen Raum möglicher Lösungen. Das Netzwerk wählt nicht irgendeine davon, es wählt eine überraschend glatte, strukturell einfache. Warum?
Der geheime Hauptdarsteller ist nicht die Architektur des Netzes, sondern der Optimierungsalgorithmus: Stochastic Gradient Descent (SGD). Er wird in der Regel als rein technisches Werkzeug beschrieben, eine Methode, um das Minimum einer Verlustfunktion zu finden. Diese Beschreibung ist korrekt, aber unvollständig. SGD ist kein neutraler Sucher. Er ist ein Filter mit einer mathematischen Präferenz.
Soudry, Hoffer, Nacson, Gunasekar und Srebro zeigten 2018 mathematisch, dass Gradientenabstieg bei separierbaren Daten implizit auf die Lösung mit der kleinsten Norm zusteuert, die Lösung mit der geringsten mathematischen Komplexität, der flachsten Krümmung, dem minimalsten Gewichtsbetrag. Im unendlich-dimensionalen Raum aller Funktionen, die die Trainingsdaten perfekt fitten, bevorzugt SGD strukturell die glattesten.
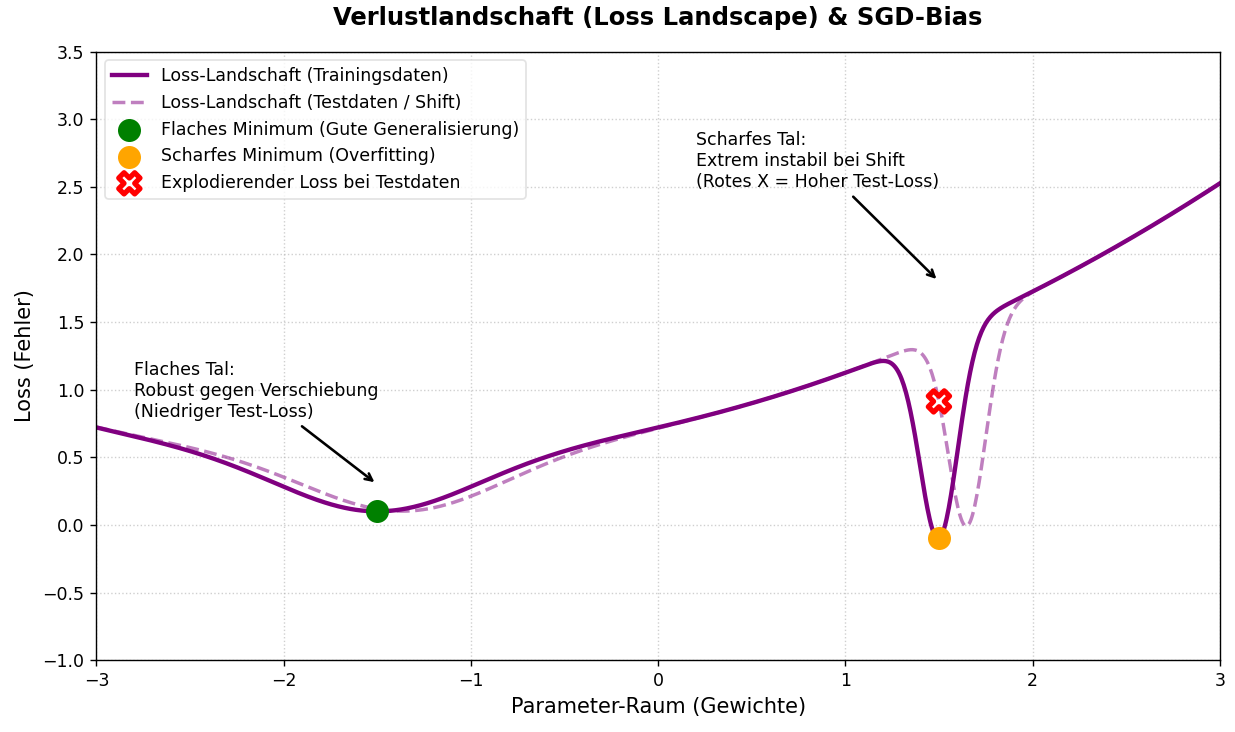
Die Geometrie der Verlustlandschaft macht das anschaulich. Hochreiter und Schmidhuber argumentierten bereits 1997, dass die Breite eines Minimums für die Generalisierung entscheidend ist. Ein schmales, tiefes Minimum bedeutet: Eine kleine Störung in den Eingabedaten, ein etwas anderes Testbeispiel, führt zu großen Ausschlägen im Output. Ein breites, flaches Minimum dagegen ist robust gegenüber solchen Störungen. Das Modell, das dort landet, generalisiert besser.
Die Analogie: Stellt man sich eine gigantische Hügellandschaft vor, in der jeder Punkt am Boden einer anderen Lösung entspricht, die alle Trainingsdaten perfekt erklärt. SGD findet nicht das tiefste, schmalste Loch, das wäre Overfitting. Es rollt in das breiteste, flachste Tal. Und flache Täler, so das mathematische Ergebnis, generalisieren systematisch besser auf neue Daten.
Dieser implizite Bias entsteht nicht durch explizite Regularisierung wie L2-Penalisierung oder Dropout. Er ist der Natur des Algorithmus inhärent, ein Nebenprodukt der Art, wie SGD den Parameterraum durchsucht. Überparametrisierung gibt SGD den Spielraum, diese Präferenz auszuspielen. Ein kleines Netz hat keine Wahl; ein großes hingegen kann unter allen perfekten Lösungen die glatteste heraussuchen.
Die praktische Konsequenz ist fundamental: Überparametrisierung ist kein Bug, sondern ein Feature. Mehr Parameter bedeuten mehr mathematische Freiheit für SGD, eine glatte, robuste Lösung zu finden. Das erklärt, warum das scheinbar naive Skalierungsrezept der letzten Jahre - mehr Daten, mehr Parameter, mehr Rechenleistung - in der Praxis so verlässlich funktioniert hat.
Gleichzeitig sollte man die Grenzen dieser Erklärung nicht unterschätzen. Das Double-Descent-Phänomen lässt sich experimentell beobachten und in Spezialfällen mathematisch beweisen. Eine lückenlose, universelle Theorie des Deep Learnings, die alle Aspekte des Generalisierungsverhaltens erklärt, warum bestimmte Architekturen bei bestimmten Aufgaben besser funktionieren, wie Datenmenge und Modellgröße optimal aufeinander abgestimmt werden sollten, existiert bis heute nicht.
Wir reiten auf einer Technologie, deren mathematisches Fundament wir gerade erst im Flug bauen. Das ist kein Argument gegen ihren Einsatz. Es ist ein Argument für methodische Bescheidenheit, und für das Interesse an den theoretischen Fragen, die noch offen sind.
Quellen
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.